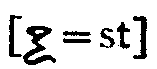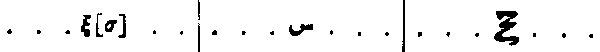I am transcoding into HTML a printed document from the early 1900's c.e. containing a mixture of Latin, Hebrew, Greek, Arabic, and (mostly) English.
Some of the names in this document contain a cryptic mixture of Greek, Arabic, and (mostly) English letters — (don't ask, I didn't write it). For example:
After the name, note the cryptic explanation of one of the letters appearing in it ...
where the equation to "st" led me to believe that the letter in question was the archaic greek letter Stigma. This letter appears in some of the subsequent names as well.
Yet when I transcode this as Unicode 03DA (that's an uppercase Stigma, lowercase looks pretty much the same, just smaller), this is the rendition I get ...
which is quite different in appearance. Interestingly, the latter is the rendition given in multiple fonts on multiple platforms, so one might presume this to be the canonical representation (if there is such a thing) of the letter Stigma.
The original also looks something like a "backwards Xi" or even a Kai, but neither of those quite mesh with the equation to "st".
Has anyone ever seen a letter resembling the original character? Could it be anything other than a Stigma? If so, it would most likely come from Coptic, Greek, Arabic, or one of the scripts of the ancient world. Or were there enough stylistic differences of ancient Greek letters to account for the, uh, uncanny unresemblance? Or is it merely a case of "printer's confusion"?
On looking over some of the author's other material, I came across a reference work of his that "equated" letters from Greek, Arabic, and Coptic (in that order). Here is the pertinent row:
We might question its earlier transliteration as "st", and the above to "s", but it's obvious the "mystery letter" is a Coptic version of the Greek ξ ("Xi").
The letter's name is evidently pronouced "eksi" and is generally considered to have the sound of "ks" or "x". See Omniglot's and Wikipedia's Coptic alphabet pages.
The Cyrillic and Coptic alphabets both derive from the Greek. So why does Cyrillic get its own Unicode code chart range, while Coptic gets the "just Greek in an Uncial font with seven extra letters from the Demotic" treatment? The difference between the lowercase Greek Xi and the Coptic "eksi" is pretty profound. It appears to be a bit more than just a font difference. Cyrillic gets a capital 'A' that looks identical to the Latin capital 'A'; Coptic appears different enough from the Greek to warrant its own code range too.